
Hi, I am Jack, a final year computer engineering student. My main responsibility in this project was to develop scripts to automate the image tagging process, by using the photos and the existing data in HKUST Digital Images for testing the potential of various computer vision models to accomplish this goal.
Object Detection, Keywords Generation, Image Tagging
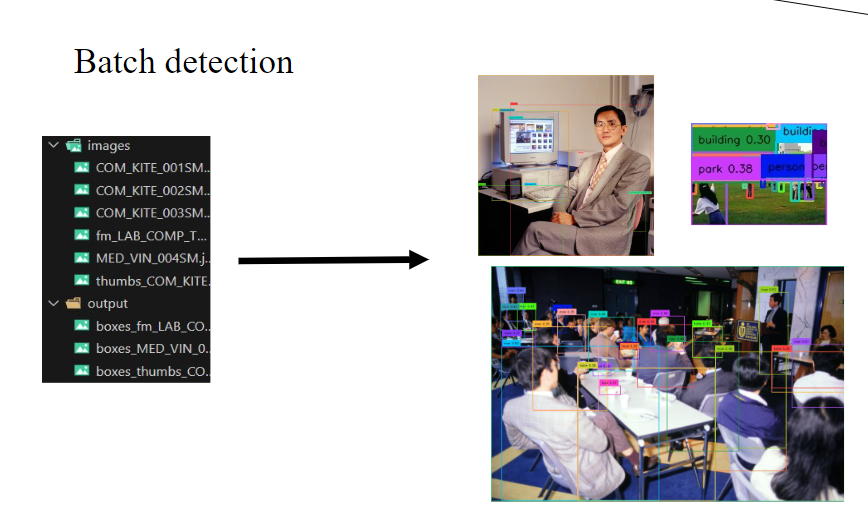
To accomplish this, I utilized two powerful models: RAM (Recognize Anything Model) and GroundingDINO. These models allowed me to extract objects and their corresponding masks from images effectively. I applied them to extract keywords from the HKUST Digital Images photos. This involved analyzing the visual content of the images and generate a set of keywords that described the objects and scenes in the images.
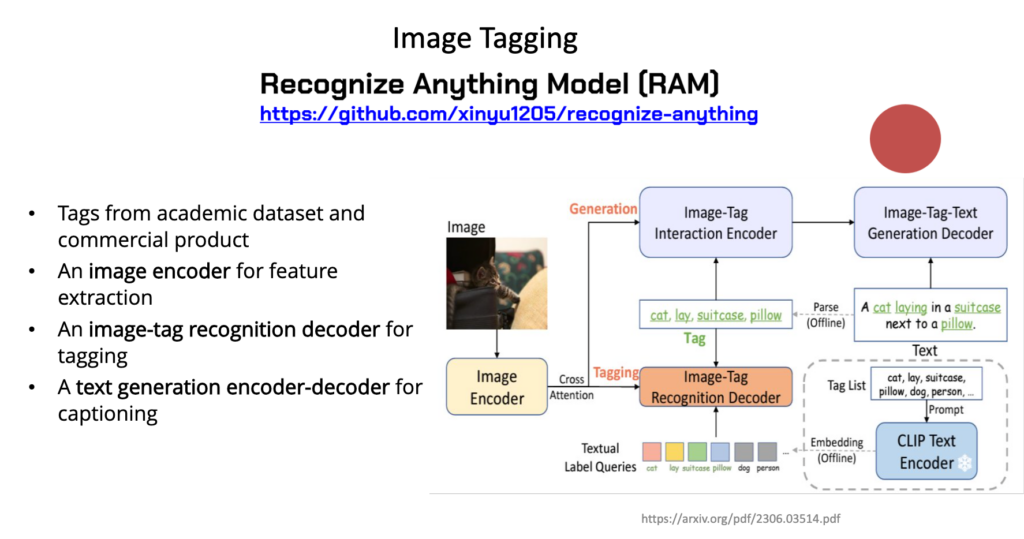



To make it easier for people to use these models, I created a number of Python scripts and Jupyter Notebooks that demonstrate the use of these models, together with a README file to provide instructions on the input requirements, output formats, and any necessary configuration or setup steps. These files allow users to quickly apply the models to their own image data by modifying a few global variables, such as the image file path. By providing these resources, I have aimed to streamline the process of using the RAM and GroundingDINO models for keywords generation. Other people can easily adapt the provided code to their specific needs, without having to fully understand the underlying model architectures or implementation details.
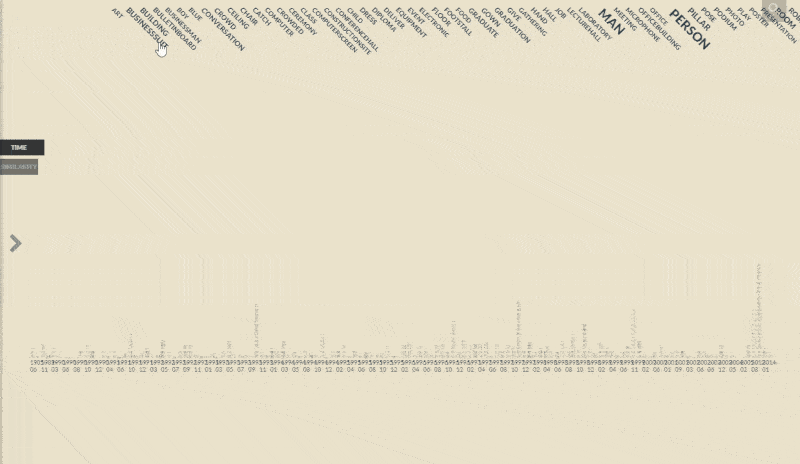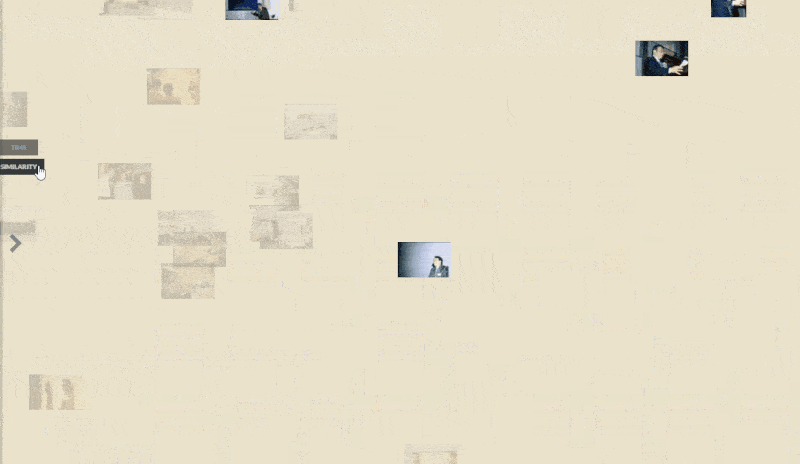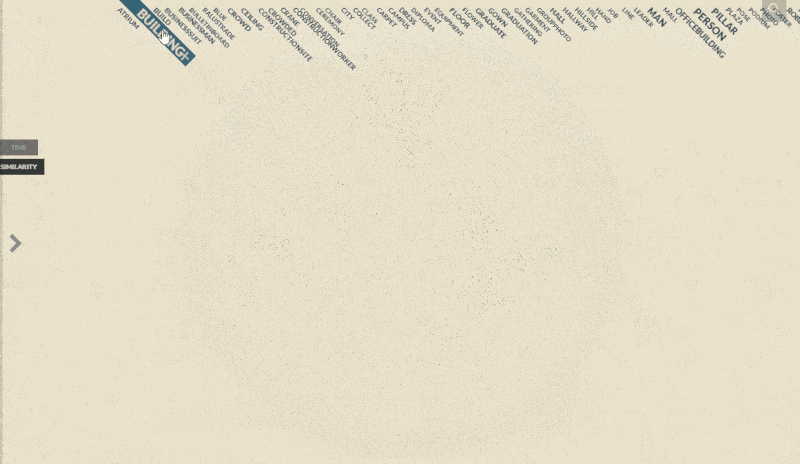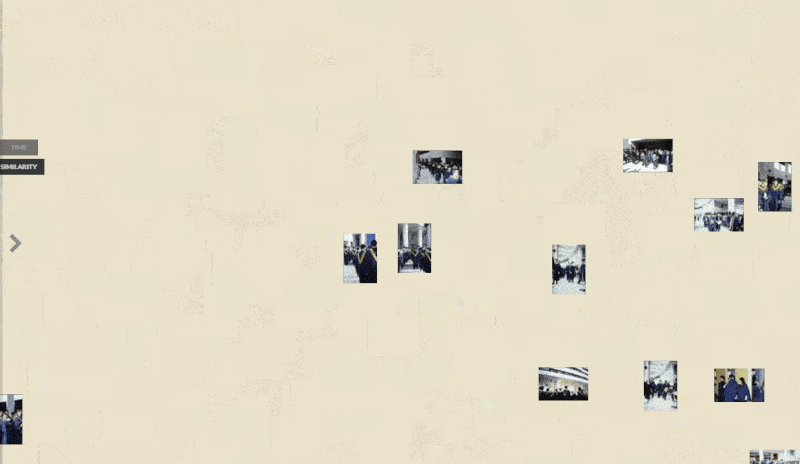
Visualization using vikusviewer
To showcase the results and make them easily accessible, I created a visualization website using vikus-viewer, a tool specifically designed for visualizing digital collections. However, I encountered some challenges along the way. One of the trickier parts was customizing the layout and style of the vikus-viewer website. Since vikus-viewer is a predefined library, it was difficult to tailor it to align perfectly with our dataset. To overcome this obstacle, I conducted a deep dive into the underlying JavaScript code of vikus-viewer and made modifications line by line, ensuring that the layout and style matched our requirements.
Face recognition
Another teammate in this project experimented with the face_recognition and deepface libraries to explore the use of face recognition techniques but challenges were found related to the performance of these methods, particularly when dealing with faces captured from different angles, such as side profiles with only one eye is shown.
To address these challenges, I tried a different approach by using a clustering-based method to analyze the similarity of facial features. The idea was to see if I could develop a face recognition system that was less sensitive to variations in head pose, potentially offering a more flexible and accurate solution. In my initial experiments, I discovered that the accuracy of this clustering-based approach was not as high as I had hoped. However, I found the learning process to be invaluable. Trying new techniques, understanding their strengths and limitations, and iterating to improve performance is an integral part of advancing the field of computer vision.
Conclusion
Throughout this project, I gained a deeper understanding of computer vision, particularly how models utilize embeddings to detect objects within an image and generate object masks. This experience significantly enhanced my programming skills and expanded my knowledge in the field of computer visions.
Overall, this part-time job in the digital scholarship service has been an enriching experience. I had the opportunity to work with cutting-edge models, tackle real-world challenges, and enhance my technical expertise. I highly recommend other students to explore similar projects in the field of digital scholarship. It not only provides practical experience but also opens doors to exciting advancements in computer vision and image analysis.


