WANG Yuning, Yolanda
Year 3, BEng in Computer Science
See below the words from Yolanda regarding her experience on this project !
Yolanda is one of our student interns who actively participated in our project about developing a Chinese Topic Modeling Tool during the 2024/25 Fall Semester (Sep-Dec 2024).
In this project, I’m responsible for developing a topic modeling tool that focused on Chinese text. This was also my first time to build web tool. After comprehensive evaluation and testing, we chose the BERTopic framework for doing the topic modeling task because it takes advantage of several language-specific models to improve adaptability and performance in processing Chinese text.
At the end, we developed key features include robust visualization capabilities that facilitate intuitive exploration of topic distributions, as well as extensive customization options. Users can adjust training parameters, manage stop words, and customize display settings to suit specific analytical needs. In addition, our tool supports various export options, allowing seamless integration into various workflows. We hope that our work could contribute to the field of natural language processing by providing a flexible and user-friendly tool for topic modeling in Chinese, promoting deeper insights and understanding of textual data.
1. Overview
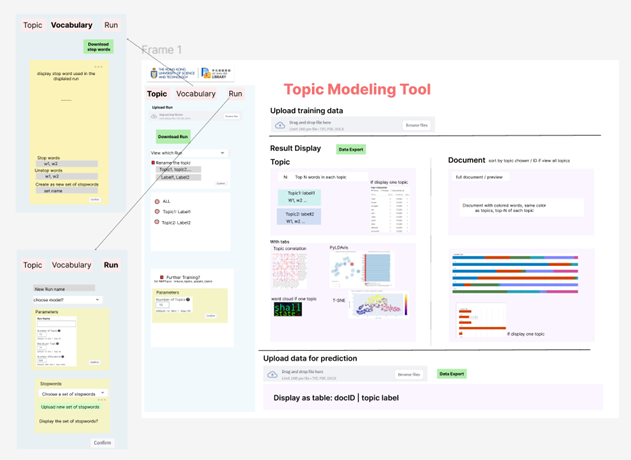
The Chinese topic modeling tool we developed comprises a user-friendly interface built on Streamlit, divided into two primary components: the main page and the sidebar.
1.1 Main Page
- Model Upload: Users can upload their pre-trained models for immediate use.
- Visualization: The page supports dynamic visualizations of topics, allowing users to explore the results interactively.
- Model Export: Users can export trained models for further analysis or integration into other applications.
- Prediction with New Data: The tool enables predictions on new datasets, facilitating real-time analysis and insights.
- Topic-over-Time Analysis: This feature allows users to observe how topics evolve over time, providing valuable context for longitudinal studies.
1.2 Sidebar
- Parameter Settings: Users can adjust various training parameters to optimize model performance based on their specific needs.
- Customization Options: The sidebar allows customization of topic displays, including the selection of relevant visual elements.
- Reset and Upload of the Model: Users can easily reset the model or upload new versions to refine their analyses without hassle.
2. Preliminary Research on Topic Modeling
This preliminary study is a crucial phase in our project as it establishes a solid foundation for the subsequent development of our Topic Modeling Web Tool. By understanding the theoretical background and assessing existing resources for suitable modeling techniques, we are better positioned to create a tool that is not only effective, but also customized to semantic characteristics of different languages. This comprehensive field study ensures that our development process is informed, strategic, and aligned with current trends in topic modeling research.
2.1 Basic Knowledge of Topic Model
Prior to this, I didn’t know anything about topic modeling. This project provided me with the opportunity to research and understand its theoretical foundations and existing techniques. Below is the summary of what I’ve learnt.
2.1.1 Concepts
Purpose of topic modeling: Identify and categorize topics within a collection of documents
| Mechanism | Common Algorithms |
|---|---|
| Step 1: Analyze the words Step 2: Determine pattern of co-occurrence Step 3: Infer the underlying topics | • Latent Dirichlet Allocation (LDA) • Non-Negative Matrix Factorization (NMF) • Latent Semantic Analysis (LSA) |
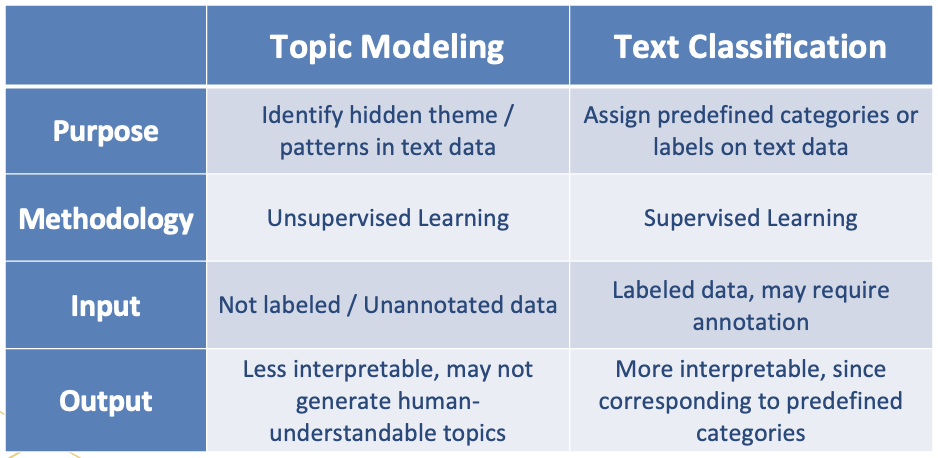
2.1.2 Differences from text classification
To further identify the specific features of topic modeling against other language-related tools, we are asked to comparing the differences between topic modeling and text classification before rolling up our sleeves to get start developing our own tool. Figure 2 concluded the differences I found.
2.1.3 Application
- Everyday Situations: Content Recommendation; News Aggregation; Customer Feedback Analysis; Social Media Analysis
- Research Scenario: Literature Review; Qualitative Research; Historical Text Analysis; Public Health Research
2.2 Environmental Scan of Existing Tools
We are then asked to do environmental scan of the following existing tools. Below is our summary after testing the functionality of these tools.
| Tool | Pros | Cons |
|---|---|---|
jsLDA: In-browser topic modeling |
|
|
Nocode functions: Free topic extraction tools |
|
|
Gale Digital Scholar Lab |
|
|
MALLET (Machine learning for language toolkit) |
|
|
Gensim: Topic modelling for humans |
|
|
3. Specifications for Chinese model
Different from alphabetical western languages like English, Chinese has a different linguistic structure together with several unique characteristics, which must be accommodated before we can use the vast functionality of the model.
3.1 Segmentation
Challenge – Word segmentation
Unlike English, Chinese text does not have spaces between words. Accurate segmentation into meaningful units (words or phrases) is crucial for effective topic modeling. This can require specialized algorithms or tools.
Solution – Jieba Segmentation Library
To split the sentences into meaningful words according to the semantic meanings, I found the Jieba Chinese text segmentation module, a useful library online.
Jieba is a popular Chinese text segmentation library that effectively splits sentences into words using several methods. It employs a pre-built dictionary containing many Chinese words and their frequencies, which helps identify valid words during segmentation.
The library primarily uses a maximum matching (MM) algorithm, scanning the text from left to right to select the longest word matches at each step. To handle words not present in its dictionary, Jieba incorporates a Hidden Markov Model (HMM)-based approach, making educated guesses about the segmentation based on context. Users can also add custom words to Jieba’s dictionary for domain-specific terminology. The library offers multiple segmentation modes, including Default Mode, which balances speed and accuracy; Full Mode, which finds all possible words; and Search Mode, optimized for search engines. Additionally, Jieba provides part-of-speech tagging, enhancing understanding of the grammatical roles of words in context. By combining these techniques, Jieba effectively segments Chinese text into meaningful words, making it a valuable tool for natural language processing tasks.
3.2 Stopwords
Stopwords play a crucial role in topic modeling and natural language processing by serving several important functions. They are common words that typically do not carry significant meaning. By removing these words, topic models can reduce noise in the data, allowing more meaningful terms to stand out and clarifying the topics being extracted. This leads to improved model performance, as focusing on words that contribute more to the semantics of the text increases accuracy and relevance. Additionally, eliminating stop words reduces the dimensionality of the text data, speeding up processing and making the model more efficient, which is particularly important for large datasets. While some words are generally considered stop words, their relevance can vary based on context. A well-defined stop word list allows for flexibility in adapting to specific domains or texts, ensuring that important terms are not inadvertently removed. Ultimately, the exclusion of stop words facilitates the generation of topics that are easier to interpret and understand, which is vital for stakeholders who need to analyze and act upon the results of topic modeling.
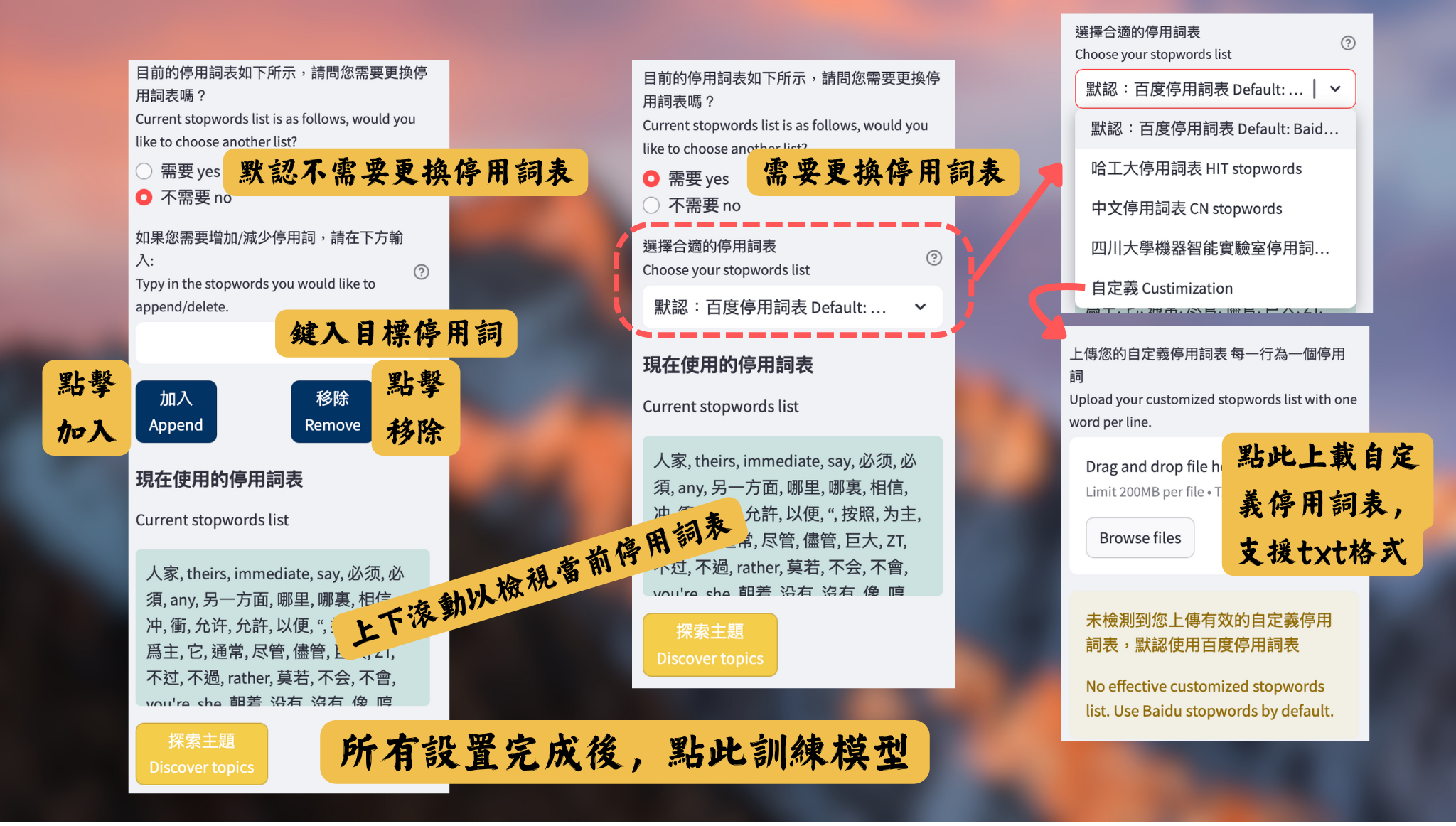
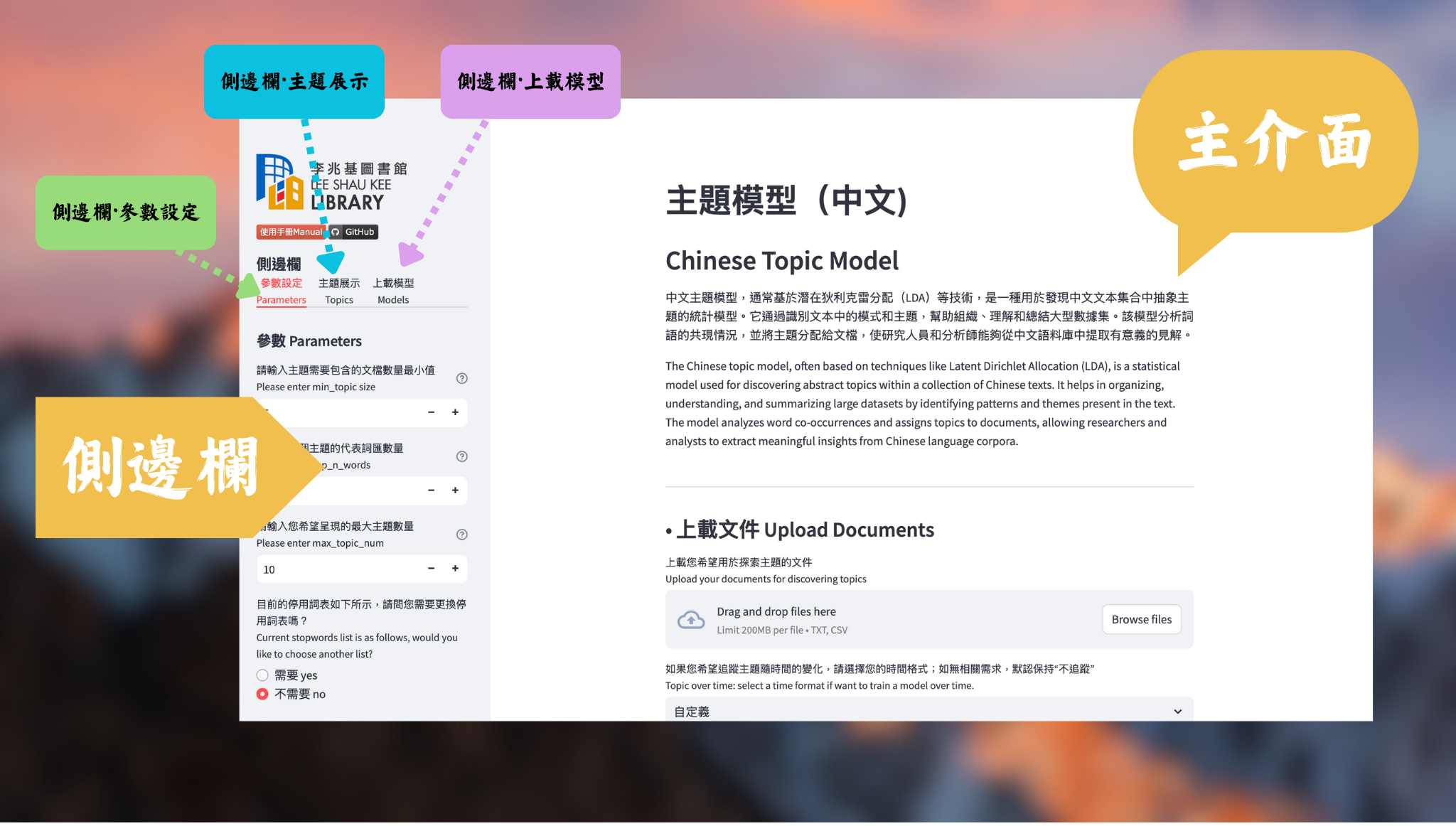
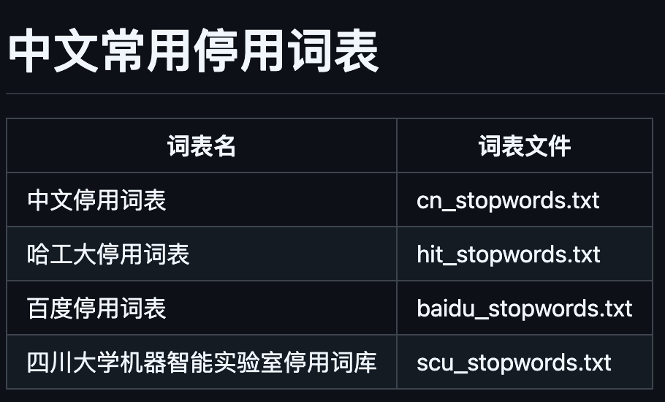
As shown in Figure 4, multiple customized settings for the stopwords are supported in our tool, so as to solve the challenges encountered during the development of the platform.
| Challenge | Our Solution |
|---|---|
| Language Structure Chinese is a logographic language with unique syntactic and semantic characteristics. Common words that may be considered stopwords in Chinese often differ from those in alphabetic languages like English. A tailored stopword list ensures the removal of irrelevant terms specific to Chinese. | Built-in classical Chinese stopwords lists To support the functionality with Chinese texts, I selected four classical Chinese stopwords lists (Baidu stopwords, HIT stopwords, Chinese stopwords and SCU stopwords) and integrated them into our tool. Users can switch among them to find the most suitable one. |
| Domain-Specific Vocabulary Different fields (e.g., technology, literature, finance) may have unique sets of stopwords. A specialized list allows for better adaptation to the domain of the text being analyzed, improving the relevance of the topics identified. | Enable user-defined stopwords In order to enhance the adaptation of the tool, our model allows users to upload their own stopwords list. In this way, users can edit their own stopwords file to play with the model, in case that the documents they use to train the model are in a specific area and has some common words which are expected to be eliminated. |
| Dynamic Nature of Language The usage of words can change over time, especially in a language as rich and evolving as Chinese. A tailored stopword list can be regularly updated to reflect contemporary language use and trends. | Enable the add / delete function of stopwords After some runs, the user may wish to slightly modify the current stopwords list, according to the previous training results. In this case, users can directly add or delete some certain words. |
3.3 Embedding model
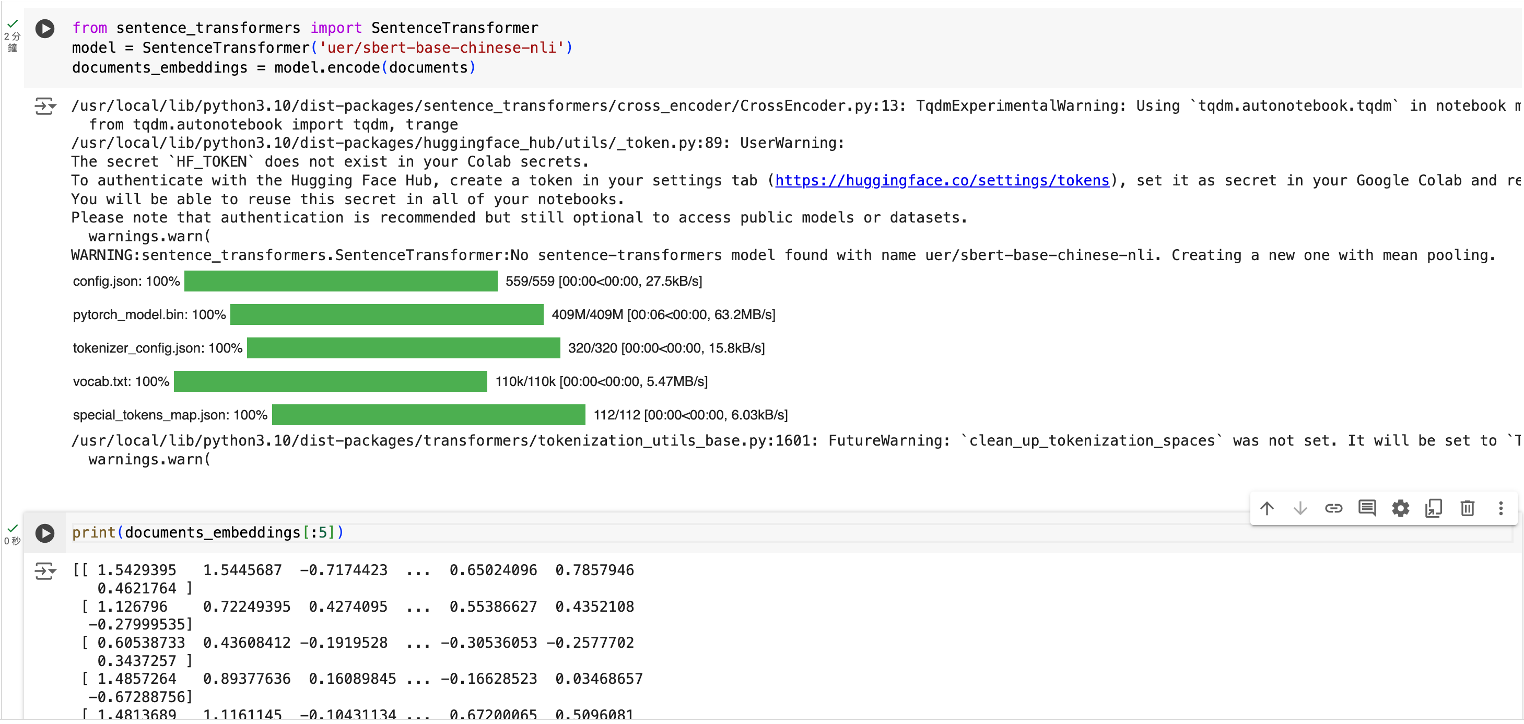
Obviously, a Chinese BERT model is required for the model to work effectively on Chinese texts. In this method, I applied the SBERT model called “uer/sbert-base-chinese-nli” from Huggingface. It generates contextual embeddings for words and sentences, meaning that the representation of a word depends on its surrounding context. This allows BERTopic to capture the nuanced meanings of words in different contexts, leading to more accurate topic representations. By using this BERT, BERTopic can measure the semantic similarity between documents more effectively. This helps in clustering similar documents together, which is essential for identifying coherent topics from the data.
3.4 Visualization
Currently, popular topic models support mainly alphabetical languages. In this case, the built-in visualization effects are usually implemented based on the characteristics of Western languages. Also, some default fonts in these visualization options cannot support Chinese language display. Thus, some of them may not display the Chinese texts correctly. To tackle this, I went through the source code of the visualization functions and making necessary modifications. In the end, I was able to resolve the problem successfully.
4. First Trial: Contextualized Topic Model
Initially, I chose the Contextualized Topic Model (CTM) to be the primary basis of the our Chinese Topic Modeling Tool due to its multilingual support.
4.1 Introduction of Contextualized Topic Models (CTMs)
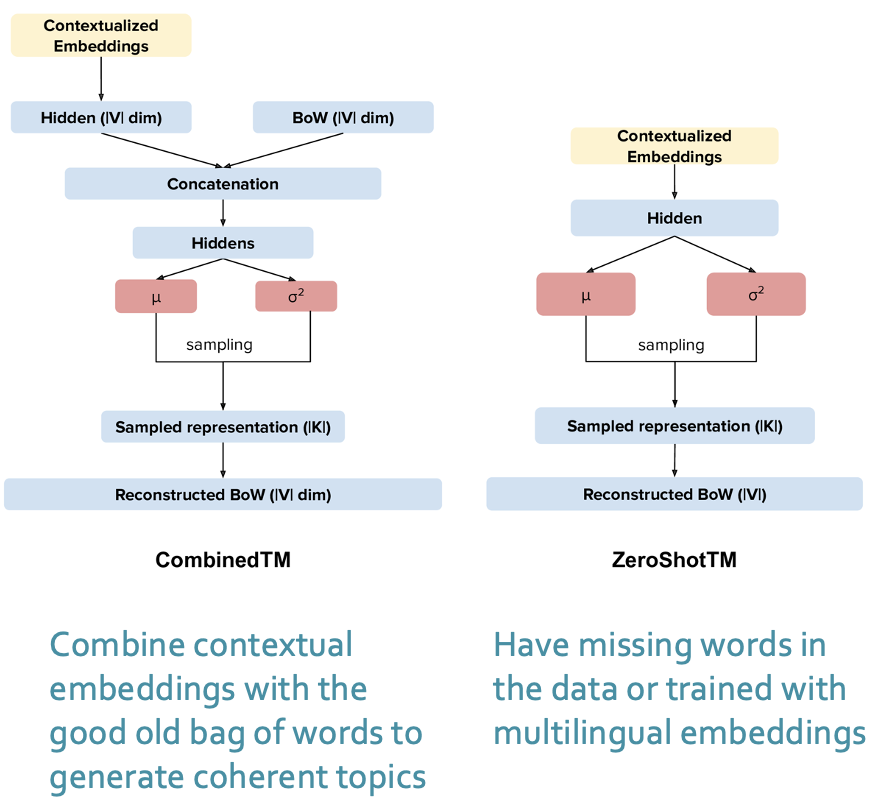
Contextualized Topic Models (CTMs) represent a significant advancement in the field of topic modeling by integrating contextual information from text data into the traditional topic modeling framework. Unlike conventional models that rely solely on word co-occurrence to identify topics, CTMs leverage contextual embeddings, allowing for a deeper understanding of the semantics behind the text. Among the notable approaches within this domain are CombinedTM and ZeroShotTM, both designed to enhance the interpretability and flexibility of topic modeling.
CombinedTM is a powerful approach that integrates the strengths of both traditional topic modeling techniques and neural embeddings. By combining the probabilistic nature of topic models with the rich contextual representations provided by models like BERT, CombinedTM enables the extraction of topics that are not only coherent but also semantically rich. This hybrid approach allows for the inclusion of contextualized word embeddings, ensuring that the identified topics reflect the nuances of language use in specific contexts.
ZeroShotTM, on the other hand, introduces a novel paradigm for topic modeling by allowing for the identification of topics without the need for labeled training data. Utilizing pre-trained language models, ZeroShotTM can infer topics from new, unseen data by leveraging semantic similarities to previously learned topics. This capability is particularly beneficial in scenarios where labeled datasets are scarce or where rapid adaptation to new domains is required. By employing contextual embeddings, ZeroShotTM can effectively discern underlying themes in diverse texts, making it a versatile tool for exploratory data analysis.
4.2 Example demonstrating the training process
In order to add the adaptability of the model to Chinese texts, I made several modifications for the data-preprocessing, model-training and visualization stages, which are demonstrated in detail in Section 3.
In order to examine the feasibility of the model, a small randomly generated dataset is fed to the model for training.
After training 10 epochs with 20 components remained, the output is as Figure 8.

4.3 Limitation
Although the model performed well with the small sample dataset, I later found that there are potential risks . When trained on real datasets, the model’s performance appears more uncertain, which could impose additional constraints on users and adversely affect their experience.
4.3.1 Data size limitation
The transformer model from Hugging Face has a maximum limit of 512 tokens per input sentence. Therefore, if any input sentence exceeds this limit, it must be either truncated or split. Truncating the sentences may result in outcomes that do not accurately represent the full context of the input. Conversely, splitting the sentences significantly increases the model’s time complexity. Consequently, this size limitation can adversely affect the model’s performance.
4.3.2 Execution cost
Even with a small training dataset, the training process takes approximately 10 minutes using the CPU provided by Google Colab. Due to resource limitations, running this model on a GPU is not feasible. Real-world usage of this model will require an extensive amount of time to complete execution, which is impractical.
5. Switch to BERTopic Model
5.1 Introduction of BERTopic
BERTopic is a state-of-the-art topic modeling technique that uses transformer-based embeddings, particularly those generated by models like BERT (Bidirectional Encoder Representations from Transformers). Unlike traditional topic modeling methods, which often rely on bag-of-words representations, BERTopic captures the semantic meaning of words within their context, allowing for more nuanced topic identification.
The model first generates dense embeddings for the documents using a pre-trained transformer model, which are then clustered using techniques such as UMAP (Uniform Manifold Approximation and Projection) and HDBSCAN (Hierarchical Density-Based Spatial Clustering of Applications with Noise). This two-step approach enables BERTopic to identify coherent and interpretable topics across large datasets, making it highly effective for exploratory data analysis.
5.2 Additional functions
BERTopic provides various functions, supporting the training, prediction, visualization and evolution of the topics. Based on this, we further added several new features to improve the user experience when using our tool.
5.2.1 More visualization tools
The original BERTopic model supports various visualization methods, including bar charts, intertopic distance maps, similarity matrices, document-topic 2D relations, and document-topic data maps. However, some of these visualizations have been adapted to better accommodate Chinese inputs, as explained in Section 3.4.

Based on this, we added two more visualization approaches to our tool which are word cloud and document-topic heatmap.
Word Cloud
A word cloud is a visual representation of text data where the size of each word indicates its frequency or importance within a dataset. Words that appear more frequently are displayed in larger fonts, while less common words are shown in smaller fonts.
Word clouds provide quick insights by offering an immediate visual summary of text data, making it easy to identify prominent themes and concepts at a glance.
Additionally, word clouds assist in content analysis by highlighting frequently occurring words, allowing users to focus on significant terms that may warrant further investigation. I’ve used the library wordcloud to generate corresponding visualization images.

Document-Topic Heatmap
We’ve also created a heatmap indicating the probability that each document belongs to each topic visually, represents the strength of association between documents and topics generated by the model. It allows users to see which documents are most closely related to specific topics, helping to identify key themes or subjects within the dataset. By observing patterns in the heat map, users can cluster documents based on their topic affiliations, facilitating better organization and understanding of the content. Additionally, it helps in exploring overlaps between topics, showing documents that may belong to multiple topics, thus highlighting the complexity of the data.
In our tool, the heatmap is generated by using the heatmap function of seaborn library. Since there are always many more documents than topics in the real-life training, the documents are splited into batches to be displayed for a more user-friendly browsing experience.
5.2.2 Import/Export settings
Originally, the export function provided by the BERTopic model allowed users to download data or models only to the same directory as the model, which might not be user-friendly for a web tool. To improve this experience, we made use of the “download_button” function in Streamlit, enabling files to be saved directly to the browser’s Downloads directory.
Additionally, as mentioned in Section 3.3, the Chinese Topic Model involves specific embedding models, making it essential to save the embedding information alongside other data when saving the model. Therefore, it is recommended to save the model with the “serialization” set to “safetensors” and as a folder of files.
To facilitate saving to the Downloads directory, I designed the flow as below: Each time a user saves a model, a temporary directory is created, and the corresponding folder is saved there. This folder is then zipped, and the archive file’s path is passed to the “data” parameter of the “download button” function in Streamlit. Similarly, when a user wishes to upload a model, the unarchived files are stored in the temporary directory for later import into the model.
6. Reflection and Conclusion
Throughout the past four months, I’ve been on a cool journey to develop a Chinese Topic Modeling tool. This project was not without challenges; initially, I attempted to build the model using the Contextualized Topic Model (CTM) but found its significant limitations related to size and time complexity in the early-stage of development. These obstacles made me realize the importance of selecting the right modeling approach for specific linguistic contexts. Transitioning to the BERTopic framework proved to be a pivotal decision. The adaptability and performance of BERTopic, particularly in processing Chinese text, allowed me to further work on the development effectively. This shift not only enhanced the tool’s efficiency but also enriched its capabilities, enabling robust visualizations that facilitate intuitive exploration of topic distributions.
A significant aspect of my learning experience was mastering Streamlit, a tool I had never encountered before. I dedicated considerable time to understand its features and functionalities from scratch, including how to create interactive web applications for data visualization. Streamlit’s simplicity and flexibility allowed me to integrate the functionalities into a cohesive user interface, ultimately resulting in a more engaging and user-friendly experience for the end users.
In conclusion, this project has significantly broadened my knowledge in the field of natural language processing by developing a flexible tool for topic modeling in Chinese. Through overcoming initial challenges and refining my approach throughout this project, I have gained insights into complex textual information. I also hope our tool would be useful for researchers in the need of topic modeling, bridging the gap between language and technology. This experience has not only deepened my technical skills but also reinforced the value of adaptability and innovation in research field.