





The Power of Retrieval Augmented Generation (RAG) LLM-based Academic Search Engines
Recently, Mr. Aaron Tay, a librarian from Singapore Management University gave us a guest talk on RAG-based LLM applications for academic literature search. This post summarizes the key insights in the presentation.
Enhancing LLM Outputs with Retrieval Augmented Generation
Large language models like GPT can generate text based on prompts and pre-existing knowledge. However, they often lack factual accuracy, especially in performing complex and knowledge-intensive tasks. This issue, known as hallucination, becomes more apparent in such scenarios.
To address this, a technique called Retrieval Augmented Generation (RAG) incorporates a search or retrieval component, such as a real-time search engine, during the prompting process. This allows the model to pull in relevant data from external sources and incorporate it into the generated response, improving the accuracy of the outputs (Figure 1).
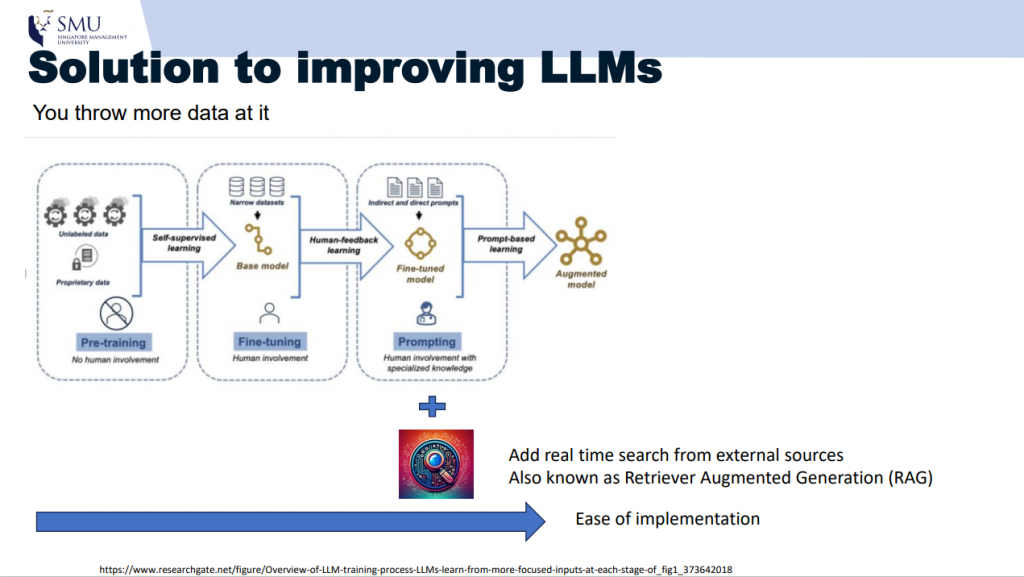
Figure 1. RAG (Retrieval Augmented Generation) - Solution to improving LLMs
In scholarly academic search, it is crucial to have information that is factually supported by evidence or citations. RAG-based tools can leverage various sources like web servers and PDF full-texts to enrich the responses with contextual information. This improves the overall accuracy of the generated outputs. Mr. Aaron Tay summarized a list of currently available and upcoming RAG-based tools in a table (Figure 2).

Figure 2. A lot of generative search engines are based on RAG, and more are coming.
Many tools mentioned in the table are available on free to premium pricing model. It’s worth pointing out that HKUST has a full subscription to scite AI Assistant, so do give it a try if you have not yet created an account.
Context Window Limitations Exist Even in GPT-4
The context window in a language model refers to the amount of text considered when making predictions. Aaron highlighted that while newer models like GPT-4 Turbo have larger context windows (120k tokens, which is around 70k to 80k words), they still face limitations in finding the right document answer when placed in the middle. This implies that if we want to process large, long texts, it is best to feed documents that carry possible answers at the beginning of the prompting (this is similar to the primacy/recency effect known from humans). Since context window limitation is persistent even with ample token sizes, RAG search technique becomes even more important to look for or verify answers from external sources.
Harder and Harder to "Explain" Results
Aaron also highlighted the increasing difficulties of explaining results yielded by generative search engines due to the relevancy rankings used in LLMs. Different search engines require different approaches when formulating queries. A user might need to apply different search strategies when navigating through different type of search tools:
- For Google or Google Scholar, keyword searches are still effective - "Open access citation advantage"
- For elicit or scite, natural language queries should be used - "Is there an Open Access Citation advantage?"
- Some GPT models require more context in the prompts, such as adding a "persona" to the query - "You are a top researcher in the subject of Scholarly communication. Write a 500 word essay on the evidence around Open Access Citation advantage with references."
Balancing Fluency and Utility in Citation Precision
Aaron pointed out an interesting finding about citations used to support the generated sentences. In a paper comparing different generative search engines, including Bing Chat, Perplexity, Youchat, and NeevaAI (now acquired by Snowflake) , it was found that responses from these existing generative search engines are fluent and appear informative, but frequently contain unsupported statements and inaccurate citations: on average, a mere 51.5% of generated sentences are fully supported by citations and only 74.5% of citations support their associated sentence.
Moreover, it was found that citation recall and precision are inversely correlated with fluency and perceived utility – responses that are fluent and appear more helpful often have lower citation recall and precision. The researchers hypothesize that citation precision is inversely correlated with perceived utility because generative search engines often copy or closely paraphrase from their cited webpages. This improves citation precision because copied text is often supported by the cited webpage but decreases perceived utility when copied statements are irrelevant to the query or the rest of the generated response.
Summary
The integration of RAG into academic search engines represents a significant advancement in combating hallucination. While challenges such as managing context windows and addressing citation precision exist, the potential for improved accuracy and usability is clear.
The recording of the webinar is available via this link.
