





What is Digital Humanities?
As a highly cross-disciplinary community, Digital Humanities (DH) brings digital methods to bear on traditional humanities scholarship, yet it is not intended to replace the traditional humanities. Rather, it creates new research methodology that allows humanities scholars to critically use big data in the digital age.
The definition of DH, or “What is DH?”, has been asked for years, yet no conclusion has been reached as components of DH continue to develop and evolve. On https://whatisdigitalhumanities.com/, every time we refresh the page, there is a new definition of DH. The diverse nature and applications of DS as an evolving field of study can also be reflected by a word cloud pulled from a corpus of definitions from the “Day of DH” (Fig.1).

Figure 1. Word cloud of high frequency words in the 791 definitions of DH from “Day of DH” between 2009 and 2014
Historical Big Data
In humanities, there are “born digital” data and digitized data produced through mass digitization processes.1 The use of big data in the humanities potentially shapes the way humanities scholars consider and examine research questions. An example of the application of historical big data is “China Government Employee Database – Qing (中国历史官员量化数据库(清代)),” conducted by the Lee–Campbell Research Group at HKUST. The project constructed a dataset from surviving editions of Qing civil officials (縉紳錄) and military officials (中樞備覧) for studying Qing bureaucracy.
Network visualization can show the underlying agents and structure in texts and images. “Six Degrees of Francis Bacon,” a DH project created by Carnegie Mellon University and Georgetown University, precisely describes the social network of early modern Britain. The project not only answers the question “Do you know if Francis Bacon knew Thomas Hobbes? (Fig.2),” but also reveals the inherent gender bias of the written records. The project constructed a database with biographic records from the Oxford Dictionary of National Biography. Of the 16,000 entries, women accounted for only 6%.2
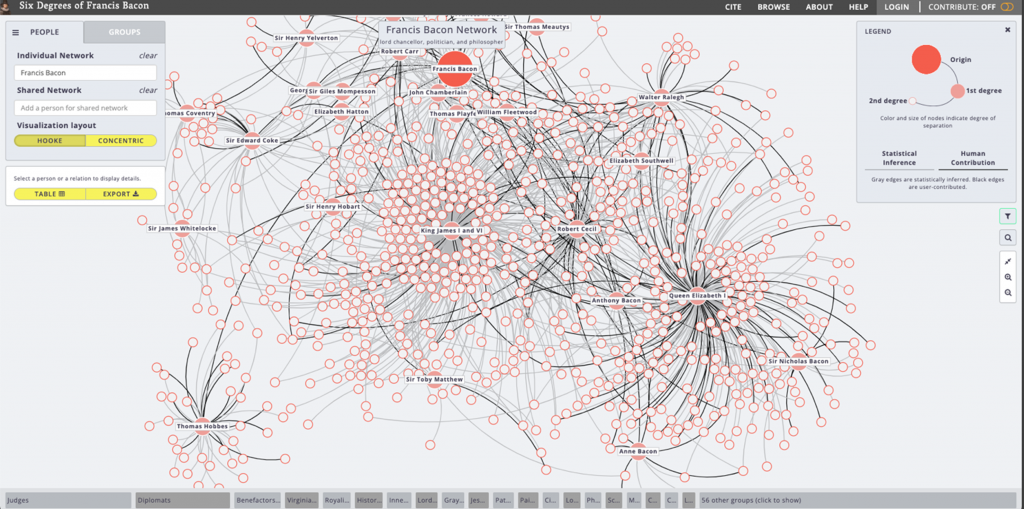
Figure 2. Screenshot from Six Degrees of Francis Bacon, showing the network of Francis Bacon
Through building databases, networks, hypertextualization, and text mining, historical big data projects not only offer the metadata for research use, but also reduce biases and limits in the existing knowledge system. The most challenging part of a historical big data project is how to collect enough data. In most cases, historians lack adequate data due to the limited availability of historical materials, which results in inaccurately trained models for machine learning.
Art History and Machine Learning
In the digital era, ways of presenting and sharing cultural and historical data have become increasingly important. The British Museum is one such organization looking to display its online collections with innovative methods. With support from the Google Cultural Institute, the British Museum launched an interactive digital exhibit, “Museum of the World.” The 3D animated timeline using Web Graphics Library technology displays the museum’s collections from a first-person perspective. More than 4,500 items in the British Museum were grouped into five categories (Art and design, Living and dying, Power and identity, Religion and belief, and Trade and conflict), and the links between the dots prompts users to compare objects from different continents in the same category (Fig.3).
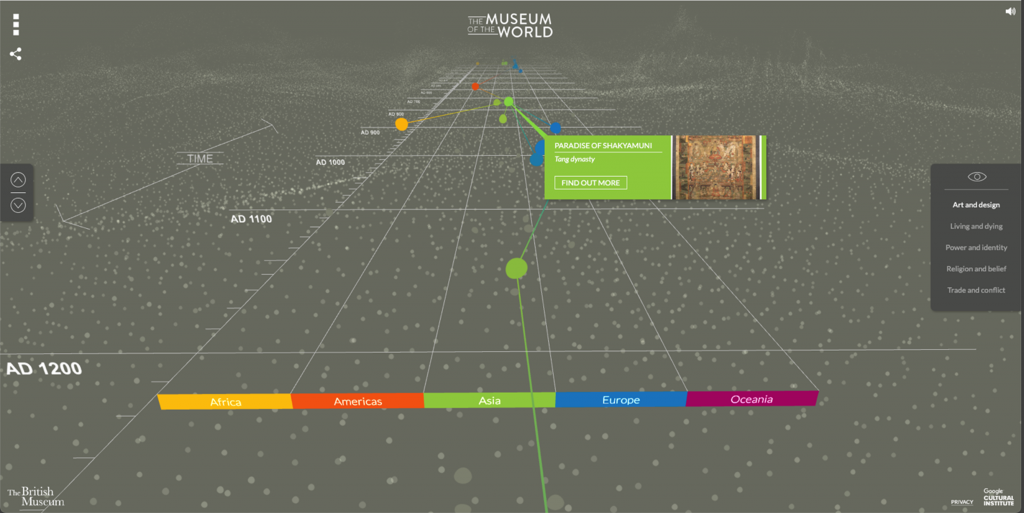
Figure 3. The Museum of the World, with an animated timeline for curating a selection of the British Museum's collection.
Machine learning algorithms can authenticate artwork by analyzing images. For a computer to analyze an image, it first needs to view a sufficient number of other images. The convolutional neural network (CNN) algorithm allows a computer to recognize images in a process called “image segmentation.” Machine learning algorithms can enhance brushstroke analysis and improve the accuracy of authenticating artworks.3 Art Recognition, a Swiss company, can achieve digital authentication with machine learning algorithms. For example, the company verified a self-portrait attributed to Van Gogh at the National Museum in Oslo. By using hundreds of original paintings, the team trained the deep CNN to authenticate the work (Fig.4). They claimed that AI classified the self-portrait as authentic, with a probability of 97%.4
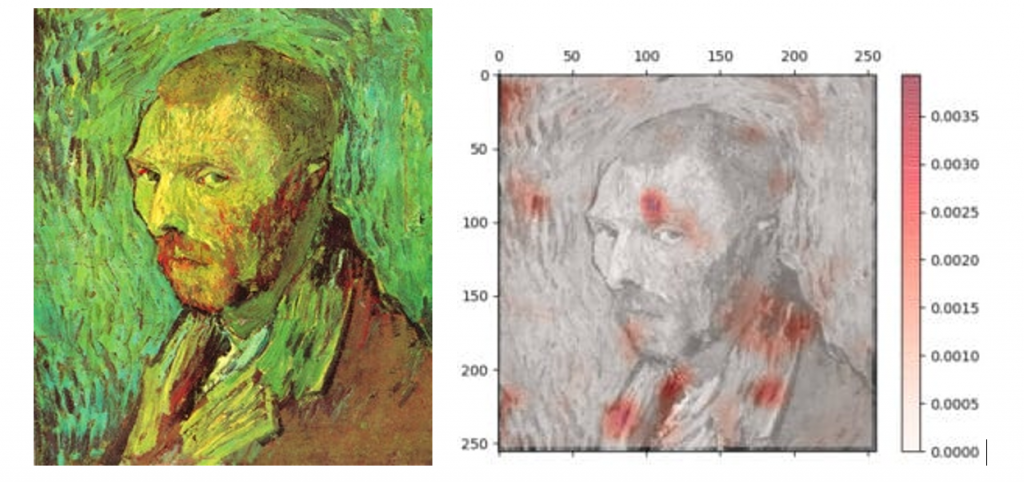
Figure 4. Art Recognition verified a self-portrait attributed to Van Gogh at the National Museum in Oslo through image segmentation
The greatest challenge for digital art historians is that there are not many high-definition original images available for machine learning training. This is especially true for artists with few surviving works. Therefore, the technique of using machine learning to distinguish forgeries from originals remains problematic.
Literary Study and Sentiment Analysis
Sentiment analysis is a natural language processing technique that identifies the polarity of a text. It is also an emerging field at the crossroads of linguistics, literature, and computer science and it seeks to automatically identify the sentiments in texts. It has been used to explore many types of literary texts, such as novels, poetry, plays, songs, social media content, etc. The Viral Texts project built theoretical models to examine why fiction and poetry “go viral” or were “reprinted” in 19th-century newspapers and magazines. Through two primary text reuse detection methods—n-gram shingling and locality sensitive hashing, the project found that anonymous mass copying of these texts made them go viral (Fig.5).

Figure 5: Screenshot of “love letter” exhibition in Viral Texts project . The phrase “sea of glory” is identified frequently in OCR-recognized newspapers
An Open and Interdisciplinary Field
Recent practices and projects suggest that DH creates new ways of thinking and practices in the humanities. DH is simultaneously a highly interdisciplinary field with many links to other disciplines such as computer science, information science and media studies. Embracing DH enables us to engage with data and technology creatively and critically.
References
- Schiuma, G., & Carlucci, D. (2018, May 8). Big Data in the Arts and Humanities: Theory and Practice (Data Analytics Applications) (1st ed.). Auerbach Publications.
- Porras, Stephanie. "Keeping Our Eyes Open: Visualizing Networks and Art History." Artl@s Bulletin 6, no. 3 (2017): Article 3.
- Lawson-Tancred, J. (2021, December 10). Can machines do art history? Apollo Magazine. https://www.apollo-magazine.com/ai-machine-learning-art-history
- Art recognition, Vincent van Gogh: “Self-Portrait” https://art-recognition.com/case-studies/vincent-van-gogh-self-portrait/
