
Inciteful: Explore Literature Using Academic Papers Graph
Unlike traditional citation databases which would yield results by keyword or topic search, Inciteful creates a graph of academic papers based on “seed papers” of your choice and helps you gain insight from it.
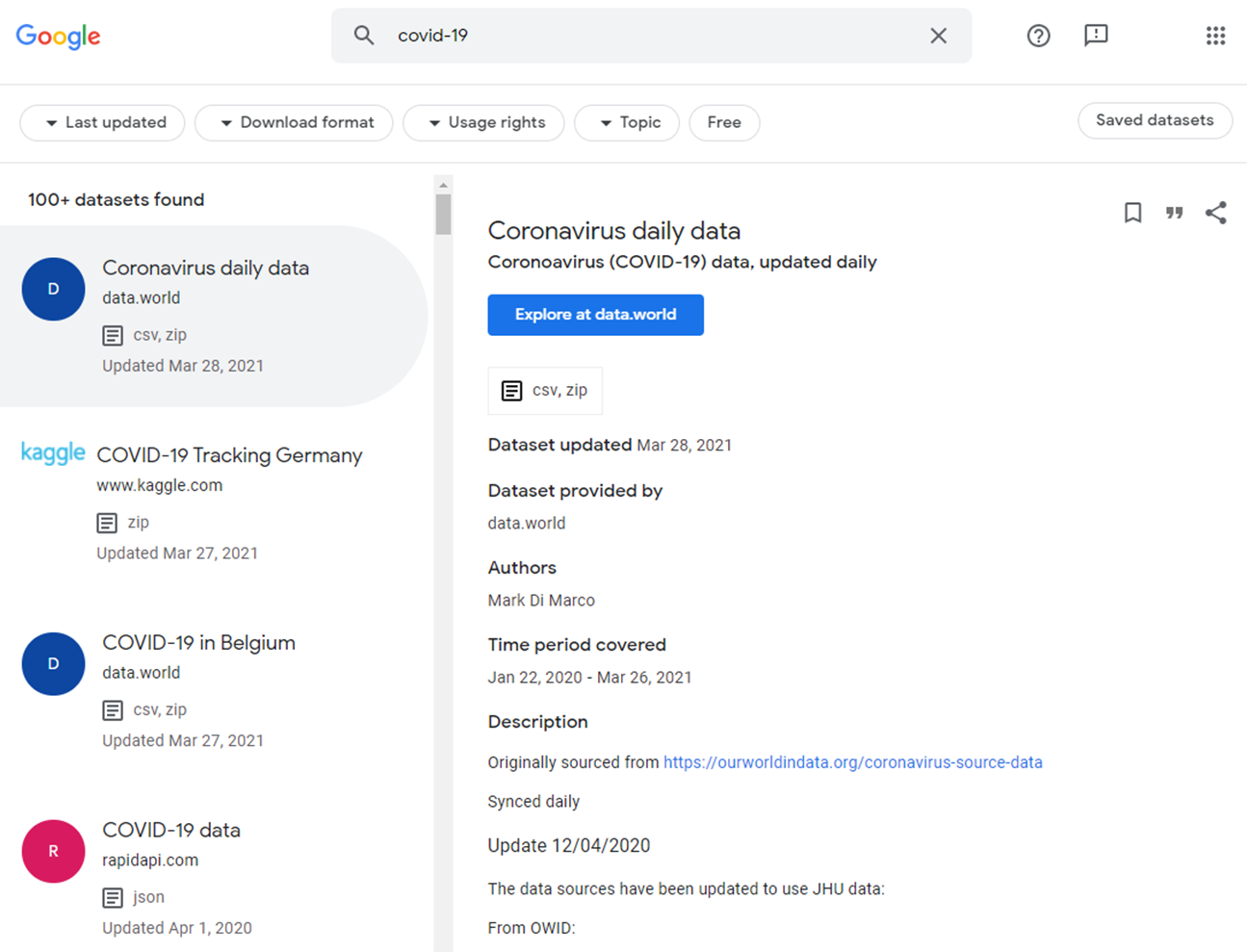 You will see data from more than 100 different data sources. The results can be filtered by last updated (past month, year, or three years), download format (table, text, image, or others), usage rights (commercial or non-commercial use), topic (subject disciplines) and if it is possible to access the dataset for free.
After reading the description and deciding the dataset is useful, you can click on the blue button to navigate to the external site for further actions.
- By
You will see data from more than 100 different data sources. The results can be filtered by last updated (past month, year, or three years), download format (table, text, image, or others), usage rights (commercial or non-commercial use), topic (subject disciplines) and if it is possible to access the dataset for free.
After reading the description and deciding the dataset is useful, you can click on the blue button to navigate to the external site for further actions.
- By