





Using Machine Learning to Link Millions of Historical Chinese Records
Why Chinese Records Are Hard to Link
China has an abundant collection of historical data. Millions of surviving government rosters, household registers, and genealogies hold the detailed life stories of countless individuals over centuries. For historians and sociologists, these records are invaluable for understanding social mobility, careers, and how institutions changed over time.
But to uncover these stories, researchers face a major challenge: accurately connecting the scattered records of a single person across different years. Unfortunately, standard automated methods often fail when applied to sources written in Chinese characters.
The root cause lies in the nature of Chinese script itself. Unlike phonetic alphabets, Chinese is a logographic system where characters represent meaning and, in some cases, sound, but not in a simple letter-by-letter correspondence. This creates three distinct obstacles for automated matching.
Phonetic ambiguity: Chinese has a very large number of homophones, meaning sound-based matching alone produces unreliable results. Standard algorithms built for Western phonetic languages cannot handle either problem.
Scalability bottleneck: Traditional linkage methods rely on manual, dataset-specific rule tuning that cannot adapt efficiently as databases grow to millions of records.
Consider this example: the characters 傅 and 傳 are strikingly similar in appearance, yet they are pronounced differently (fù vs. chuán) and carry unrelated meanings. A scribe writing in haste could easily confuse the two and a conventional record-linkage algorithm would have no way of knowing the substitution was likely. Multiplying these edge cases across vast historical databases creates a severe scalability bottleneck, making automated, adaptable solutions essential.
A Three-Stage Machine Learning Pipeline
In our latest publication in Historical Methods, we solve this by introducing an adaptable, machine learning-based pipeline designed specifically for Chinese historical databases. We also open-source the code repository on GitHub.
The system operates in three consecutive stages, each targeting a specific bottleneck in the matching process:
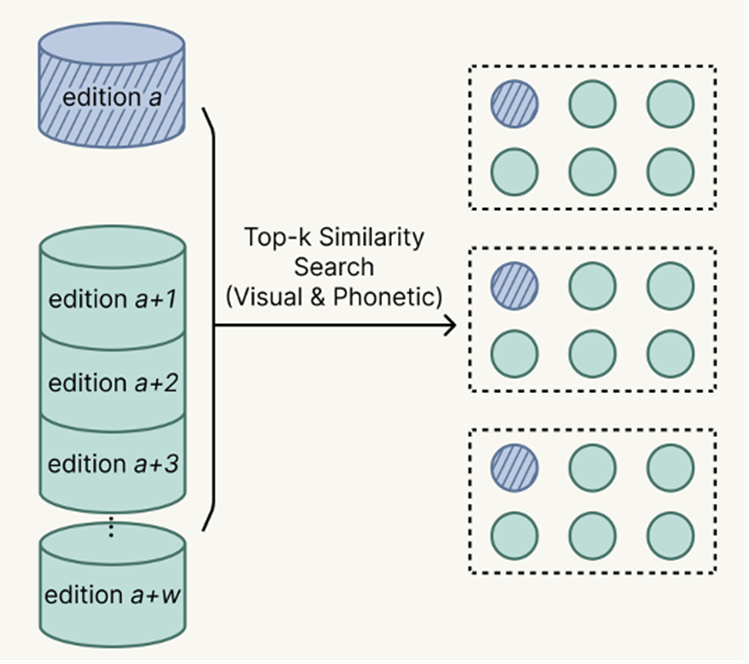
Blocking: Shrinking the Search Space
Before we can confidently match records, we have to efficiently group potential candidates to avoid comparing every single person against millions of others. To do this, the system takes a record from one historical roster (let’s call it Edition A) and performs a Top-k similarity search against a sliding window of subsequent rosters (Edition A+1, A+2, etc.). It pulls the most likely candidate matches based on two combined criteria: how the names sound (based on the similarity of pinyin) and how they look (visual similarity).
But how to teach a computer how a historical Chinese character “looks” to catch those historical visual typos? We developed a novel approach centered on stroke-based embeddings. Instead of looking at whole characters, our model breaks them down into “stroke trigrams” (sequences of three consecutive strokes). It adopts the architecture of Word2Vec, shown in the left panel of the figure below, which learns the meaning of a word based on the context of the words surrounding it. Our algorithm does the exact same thing, but with strokes (the right panel of the figure below).

By analyzing the context of these stroke trigrams, the model puts every character into a high-dimensional embedding space. Characters that share visual structures,such as 傅 and 傳, are mathematically mapped closer together. This allows the system to instantly flag visually similar candidates to group together.
Matching via Active Learning
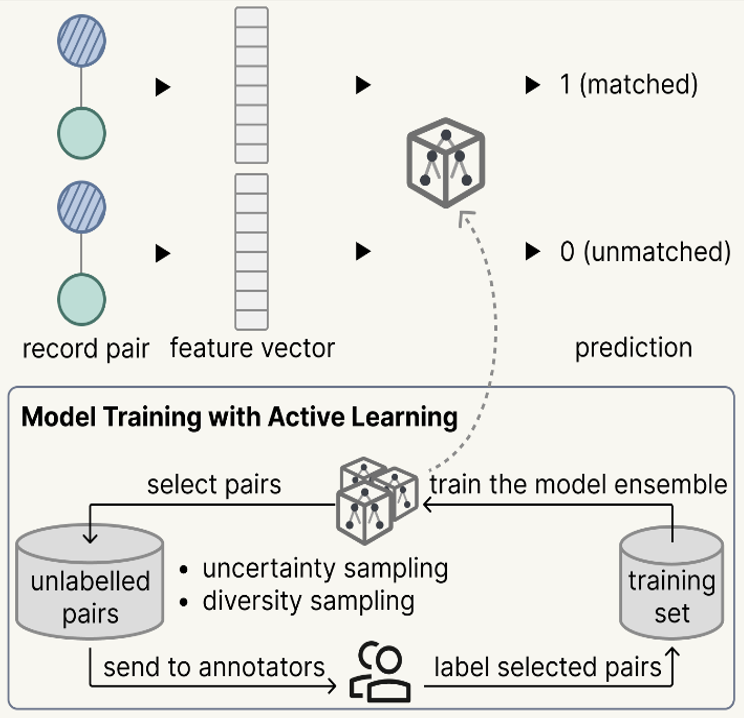
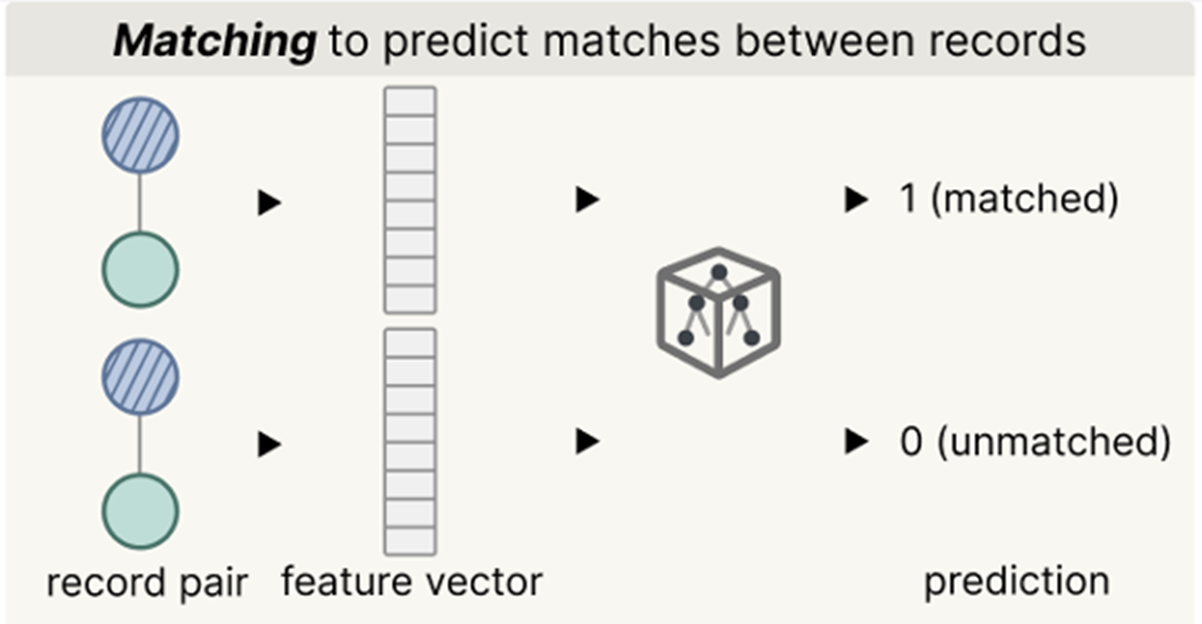
Once the blocking stage has shrunk the search space down to a handful of highly likely candidates, the pipeline needs to make a final decision: Is this actually the same person? To do this, the system evaluates the candidate pairs using an ensemble of machine learning classifiers. These classifiers look at all the available features, including the visual and phonetic similarity of their names, geographic origins, job titles, and bureaucratic ranks.
But here we hit a bottleneck again: to train a machine learning model to recognize a “good match,” we typically need a massive dataset of already-solved examples (a “ground truth” set). In the realm of Chinese Qing historical records, nobody has perfectly mapped millions of individuals yet. Asking a team of historians to manually label tens of thousands of random pairs just to train the AI is practically impossible.
To solve this, we implemented an Active Learning loop. Instead of manually labeling random data, the system works smarter:
- The AI Tries First: The model reviews a massive pool of unlabelled candidate pairs, trying to guess the matches.
- Finding the Edge Cases: If the AI gets confused or its classifiers disagree, it flags a diverse batch of these tricky pairs (uncertainty and diversity sampling).
- Human Intervention: A human expert steps in to manually label only this small, highly curated batch.
- Getting Smarter: These newly solved pairs are fed back into the system to retrain the model.
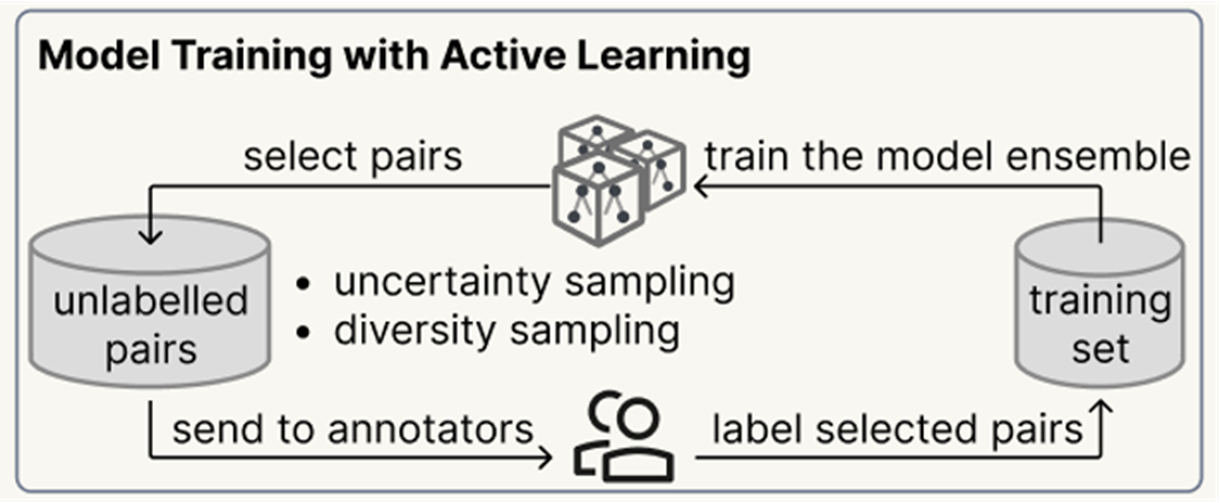
This approach achieves approximately 0.9 F1 score using only 1,000 labelled training pairs — a tiny fraction of the annotation effort that conventional fully-supervised methods would require.
Clustering
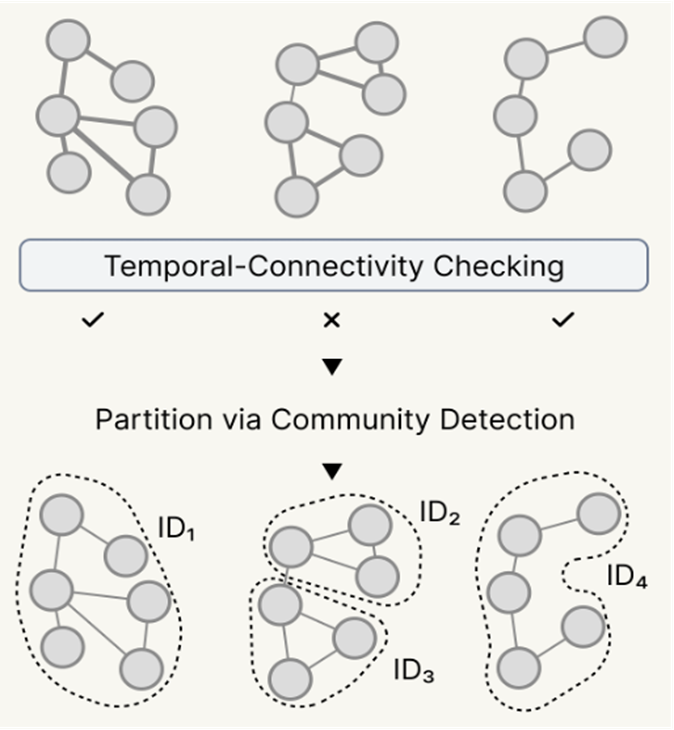
After the active learning model scores the candidate pairs, we connect all the winning matches into a massive network graph. In this graph, every node is a historical record, and the lines connecting them are the confirmed matches. Ideally, each isolated cluster of nodes represents a single person’s entire career trajectory.
But historical data is messy. A single false-positive match (say, mistakenly linking two completely different officials who share the same name) can cause a “chaining effect” that merges two large clusters together. To prevent this, the system acts as a final auditor. It performs a check based on temporal connectivity (the cluster will be labeled as suspicious if it has chronological gaps or weak links between consecutive years).
If a cluster looks structurally unsound (marked by the “x” in the figure), the pipeline deploys a partition in the network using a community detection algorithm, which looks for the weakest links and cuts the tangled network apart, separating the records back into distinct individuals. Finally, the system assigns a unique historical ID (like ID1, ID2, etc.) to each verified cluster.
Putting It to the Test
The pipeline was benchmarked against the China Government Employee Database-Qing (CGED-Q), analyzing over 1.5 million records spanning 1830 to 1904. Compared to older rule-based methods, the ML approach substantially reduced both major classes of matching error.
It even proved its capability in a highly complex cross-dataset challenge, successfully tracking officials who transitioned from the falling Qing Dynasty into the new Beiyang government. The pipeline caught hundreds of tricky matches containing scribal discrepancies, achieving a 92% precision rate in manual checks.
False Positives (wrong merging)
↓68%
Fewer cases detected as “exceptional career transitions” (cases violating promotion rules).
False Negatives (wrong splitting)
↓20%
Fewer “anomalous high-rank starts” (suggesting better links to early lower-rank records) & Longer average career length.
Cross-Dataset Precision
92%
Manual verification rate when linking Qing officials into the subsequent Beiyang government dataset.
Looking Ahead
The true power of this pipeline is its adaptability. We’re moving past rigid, manually coded rules to offer a robust, semi-supervised tool that lets the historical data speak for itself.
Moving forward, we plan to expand this pipeline beyond the civil service to map the lives of everyday people in population registers and genealogies in historical China. Because the underlying logic focuses on strokes rather than pronunciation, it can also be potentially extended to historical records from Japan, Korea, and Vietnam. By integrating advanced NLP models to better understand historical context, we are building a robust data infrastructure that will eventually help researchers connect millions of historical lives across the globe.
References
Yu, Yue, Yueran Hou, Yibei Wu, and Cameron Campbell. 2026. A Machine Learning Approach for Nominative Record Linkage in Chinese Historical Databases. Historical Methods: A Journal of Quantitative and Interdisciplinary History, March, 1–18. doi:10.1080/01615440.2026.2641454.
Campbell, Cameron, and Bijia Chen. 2022. Nominative Linkage of Records of Officials in the China Government Employee Dataset-Qing (CGED-Q). Historical Life Course Studies 12 (January). European Historical Population Samples Network (EHPS-Net):233–259. doi:10.51964/hlcs11902.
Chen, Bijia, Cameron Campbell, Yuxue Ren, and James Lee. 2020. Big Data for the Study of Qing Officialdom: The China Government Employee Database-Qing (CGED-Q). Journal of Chinese History 4 (2). Cambridge University Press:431–460. doi:10.1017/jch.2020.15.
Please see our published paper for the full reference list.
